June 16, 2026 · Carlos Crespo
The Algorithm That Reads Your Genes
Give a random forest a cell's gene-expression pattern and it can classify the cell type and show which gene markers drove the call. A look at how this older machine-learning method does real work in medicine.

You can hand a model a single cell's gene-expression pattern, which is really just hundreds of numbers describing which genes are switched on, then it turns around, tells you what type of cell you are looking at, which genes gave it away, how sure it is about the call! That still feels a little wild to me. It is also not a chatbot doing a party trick, it is a random forest, a much older, much quieter kind of machine learning, the same family of methods that has been running underneath fields like medicine and finance for years. I want to walk through how this actually works using a real project I ran on biological data, then show you how the chatbot side of AI works too, because the two are nowhere near the same thing.
What people even mean by "AI"
When we say "AI" today we almost always picture generative AI, the chatbots, the image generators, the thing you type a question into. That is the newest layer though, not the whole story. Artificial intelligence as an idea is about seventy years old, going back to the 1950s when researchers first asked whether a machine could reason at all, except for most of those decades AI meant hand-written rules, giant systems where people tried to spell out human expert knowledge one instruction at a time, which worked for narrow problems but stayed brittle, never really scaled. The real shift came when the field stopped writing rules, started learning patterns straight from data instead, which is the whole idea behind machine learning, you show a model a pile of examples, it works out the structure on its own. Random forests come straight out of that shift.

How a random forest actually works
The random forest was introduced by Leo Breiman back in 2001, the idea is honestly beautiful in how simple it is, you grow a whole bunch of decision trees, each one looks at the data a little differently, each one votes, you go with the crowd instead of trusting any single tree. That is literally where the name comes from! Show it one cell, every tree casts a vote for the cell type, the majority wins, the more trees that agree the higher the confidence. When the answer is a number instead of a category, like a price or a dosage, the same forest does regression, averaging the trees rather than counting votes.
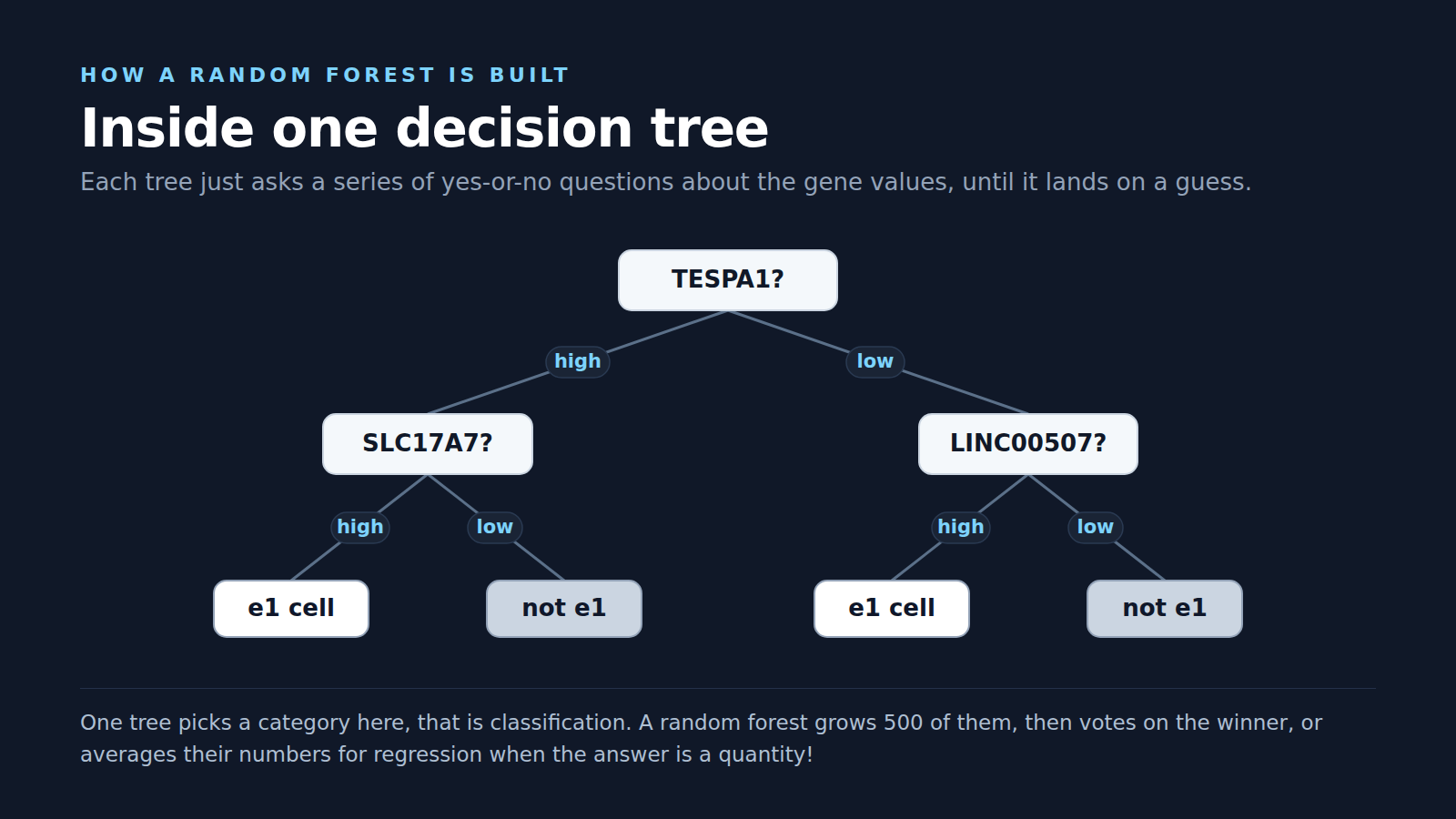
My project pointed that machinery at biological single-cell transcriptomics data, the dataset came out of research on cell type discovery, where scientists study gene-expression patterns to identify different cell types. The point was never to build a chatbot, it was to take a real dataset, train a model, test it, then ask the question that actually matters, does the model's reasoning line up with the known biology?
What the model found
The dataset had 871 samples, 608 gene-expression features, each sample labeled as either part of the e1 cluster or not, with the biological ground truth coming from published research that pinned down the e1 cluster through marker genes like TESPA1, LINC00507, SLC17A7, while KCNIP1 worked as a negative marker. After testing different settings for the number of trees, the variables sampled at each split, the classification cutoff, the best version landed on 500 trees, an mtry of 49, a cutoff of 0.3. It performed really well, hitting 99.655% accuracy with a tiny 0.345% out-of-bag error rate, then nailing both held-out verification samples, calling the positive one positive at 78.2% confidence, the negative one negative at a confident 99.4%!

The accuracy is cool, the feature ranking is the part that really got me though, because the top three ranked features came back as TESPA1, SLC17A7, LINC00507, lining up exactly with the marker genes the biology paper expected for the e1 cluster, with KCNIP1 showing up near the top too, which makes sense since it sits on the negative-marker side of the definition.
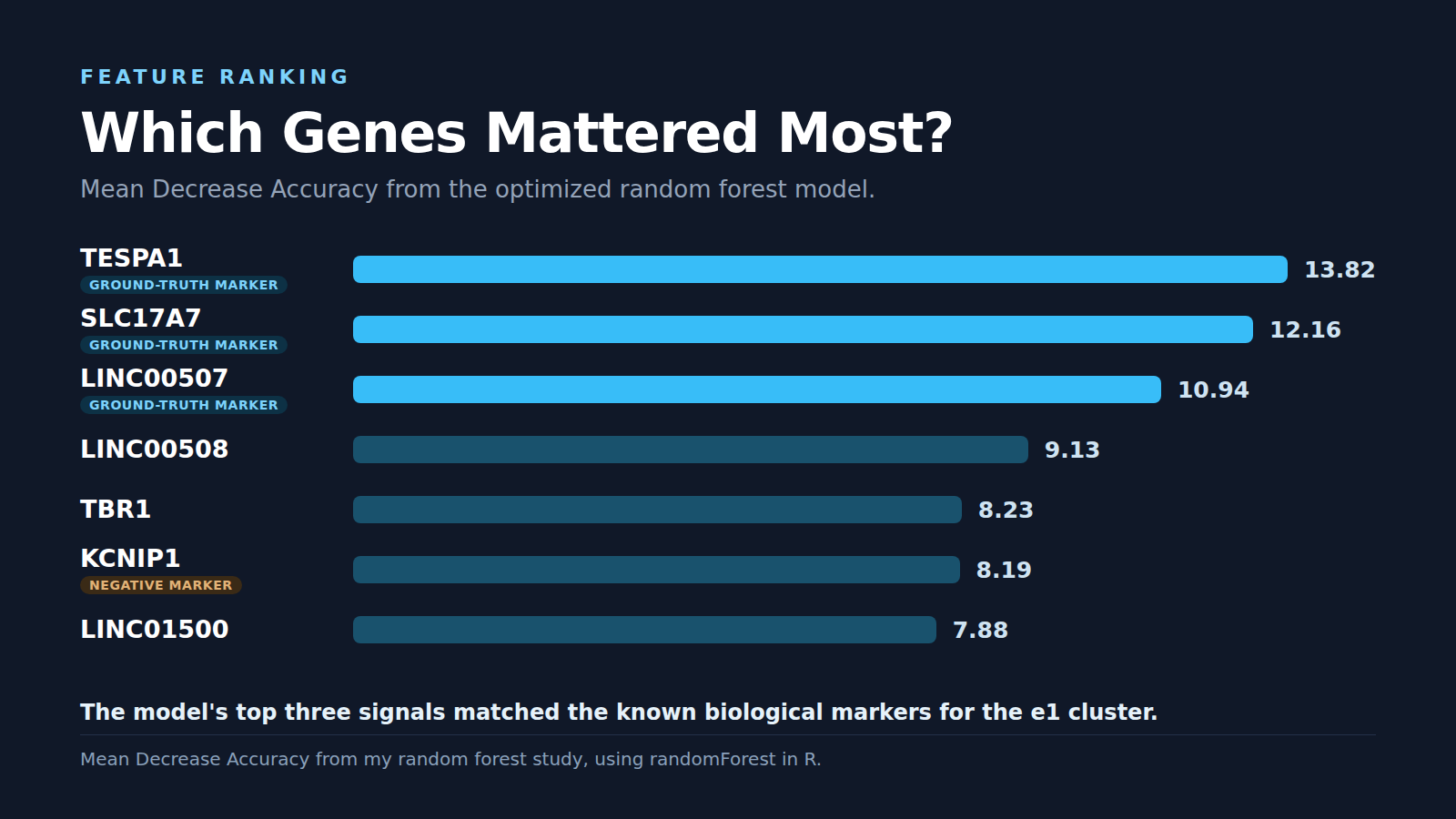
That is the takeaway I care about most, the model handed us a prediction, it also handed us a way to look back at which features drove it. In medicine that matters enormously, because if a system says "this sample belongs here" a clinician needs more than a final answer, they need to understand what signals pushed the model toward that call. Explainability is exactly where these older, data-driven methods still carry so much weight.
How LLMs work, the other kind of AI
So where do the chatbots fit? A large language model is doing something genuinely different from a random forest, it is not voting on a category, it is predicting the most likely next piece of text one token at a time. Your words get broken into tokens, the model weighs the context around them, then it produces a raw score, called a logit, for every possible next word in its vocabulary, scores that mean almost nothing on their own. That is where a step called softmax comes in, it takes those raw scores, exponentiates them, normalizes them so they all add up to 100%, turning a pile of meaningless numbers into actual probabilities, a real confidence for each option.
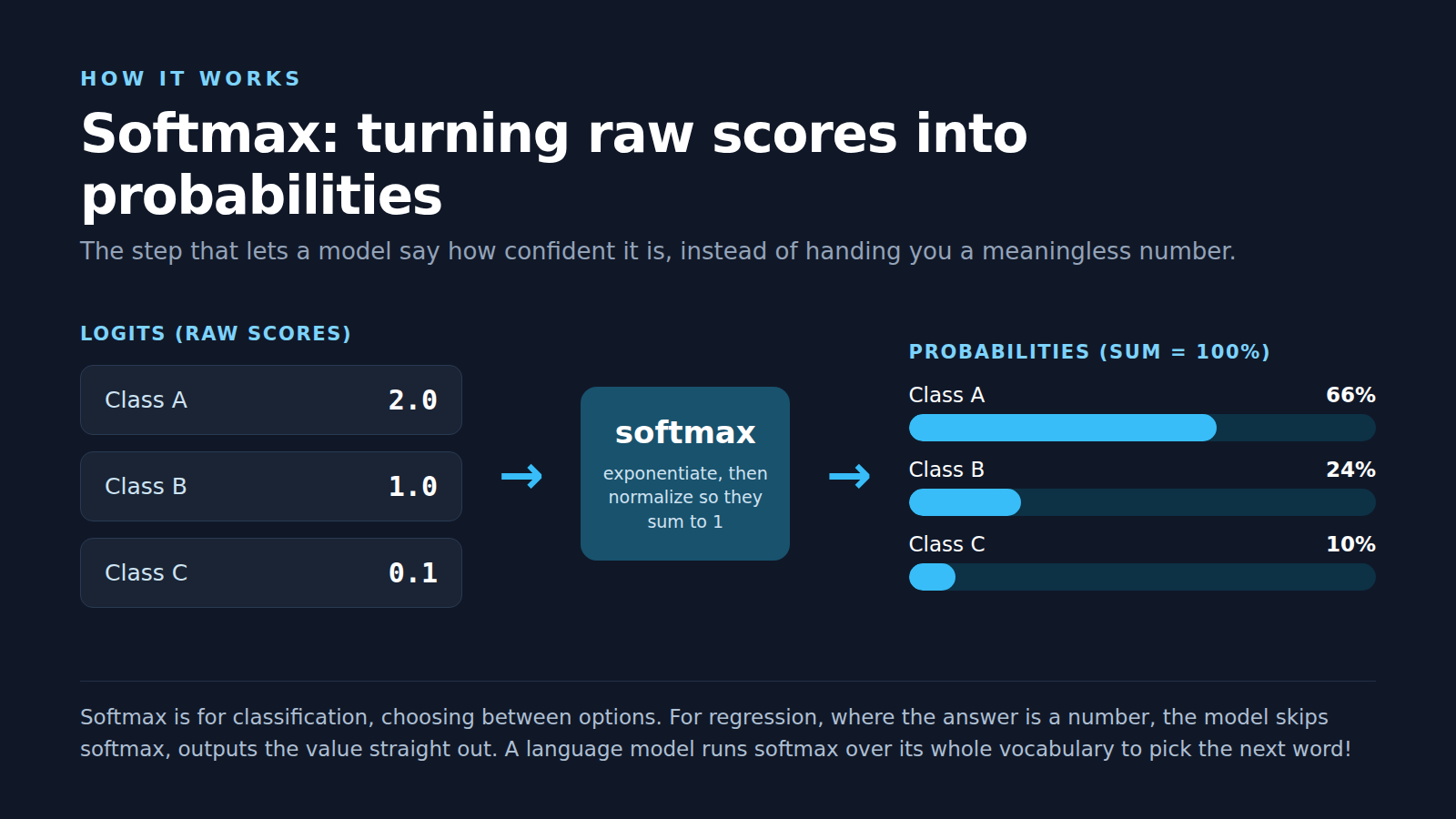
The random forest does the simple version of this by counting tree votes, the language model does the heavy version with softmax over tens of thousands of possible words, picking one, then running the whole loop again for the next word! Same underlying goal, turn the model's internal numbers into a confident choice, wildly different scale.
Who actually builds all of this
People ask me all the time who actually makes this technology, the honest answer is that "AI" rides on a surprisingly long supply chain, so here is the quick tour from raw silicon up to the chatbots, with one note first, none of this is investment advice, I am just dropping the ticker symbols so you can look the companies up yourself!
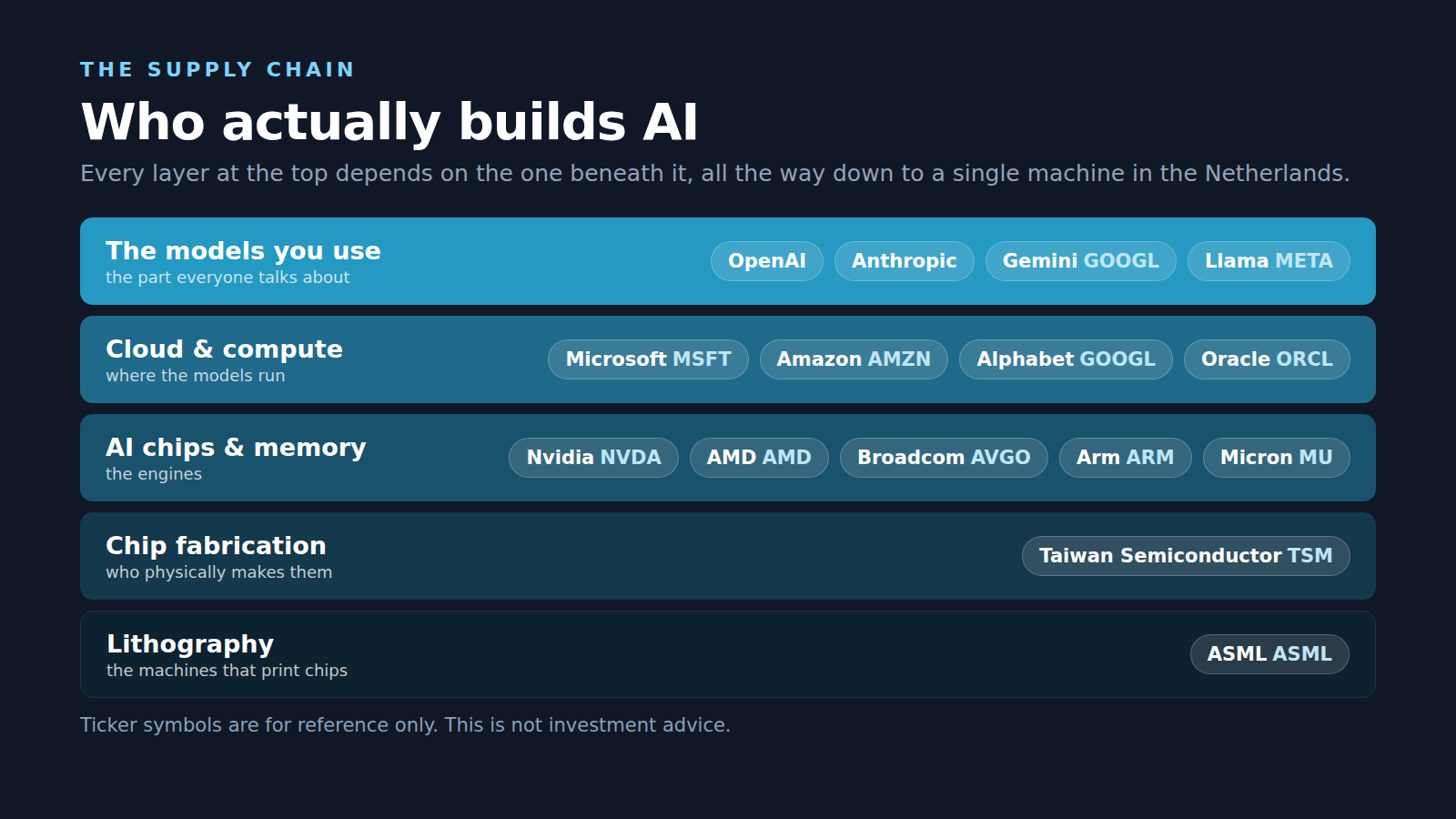
It starts with the chips, since the math behind AI runs on specialized processors, the giant there is Nvidia (NVDA) whose GPUs train and run most of the big models, with AMD (AMD) pushing hard as the main challenger, Arm (ARM) licensing much of the underlying chip architecture, Broadcom (AVGO) building custom AI silicon plus the networking that ties data centers together. Those chips do not make themselves though, which is the part most people never hear about, because the most advanced AI chips are physically manufactured by Taiwan Semiconductor (TSM), the contract foundry almost everyone leans on, with TSMC itself depending on ASML (ASML), the one company on earth that builds the extreme-ultraviolet lithography machines needed to print chips that advanced, plus a mountain of high-bandwidth memory from Micron (MU). Once the chips exist the models have to run somewhere, that somewhere is mostly the big cloud providers, so Microsoft (MSFT) runs Azure as the main backer of OpenAI, Amazon (AMZN) runs AWS with heavy investment in Anthropic, Alphabet (GOOGL) runs Google Cloud while building its own TPU chips plus the Gemini models through Google DeepMind, with Oracle (ORCL) plus Meta (META) rounding things out, Meta also giving its Llama models away for free. At the very top sit the model makers everyone actually talks about, some inside public companies like Alphabet (GOOGL) or Meta (META), some still private like OpenAI, closely tied to Microsoft, or Anthropic, backed by Amazon plus Google, so even the private labs trace right back up the same chain!
Try It Yourself
You do not need the original dataset to get the idea, the code below shows the basic shape of a random forest pipeline in R, you can swap in any CSV where the last column is the label you want to predict.
library(randomForest)
# Replace this with your own CSV.
# The final column should be the class label.
data <- read.csv("your_data.csv", header = TRUE)
data$Label <- as.factor(data$Label)
set.seed(123)
# Hold out a small sample for a final check.
holdout_index <- sample(seq_len(nrow(data)), 2)
verification_data <- data[holdout_index, ]
training_data <- data[-holdout_index, ]
# Train a random forest classifier.
model <- randomForest(
Label ~ .,
data = training_data,
ntree = 500,
mtry = 49,
importance = TRUE
)
# Check model performance.
print(model)
# See which features mattered most.
feature_importance <- importance(model, type = 1)
feature_ranking <- data.frame(
Feature = rownames(feature_importance),
Score = feature_importance[, 1]
)
feature_ranking <- feature_ranking[order(feature_ranking$Score, decreasing = TRUE), ]
head(feature_ranking, 10)
# Test on held-out samples.
predicted_class <- predict(model, verification_data)
predicted_probability <- predict(model, verification_data, type = "prob")
print(predicted_class)
print(predicted_probability)This is really the surface-level version, you load the data, hold out a few examples, train the model, check the accuracy, rank the features, then test on examples the model never saw during training, which is the step that matters most because a model that only works on data it already memorized is not very useful!
A Few Honest Caveats
This is not medical advice, it is not investment advice, it is not a claim that this model is ready for clinical use, it is a learning project! The reason I keep coming back to it is that it makes the whole stack feel less abstract, you can see one method in the lineage doing real work, you can see the exact features it leaned on, you can check its ranking against published biology, which makes it so much easier to understand why AI in medicine goes way past chatbots answering questions, since sometimes it is just a decades-old model quietly sorting through hundreds of measurements, pointing researchers toward the signals that actually matter.
Sources
- Leo Breiman, "Random Forests", Machine Learning, 2001. https://link.springer.com/article/10.1023/A:1010933404324
- Vaswani et al., "Attention Is All You Need", 2017, the transformer paper behind modern language models. https://arxiv.org/abs/1706.03762
- Aevermann et al., "Cell type discovery using single-cell transcriptomics", Human Molecular Genetics, 2018. https://academic.oup.com/hmg/article/27/R1/R40/4953379
- FDA, Artificial Intelligence-Enabled Medical Devices. https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-enabled-medical-devices
- NIH, Artificial Intelligence. https://datascience.nih.gov/artificial-intelligence
- R randomForest package. https://cran.r-project.org/web/packages/randomForest/index.html
Get the next post in your inbox.
A new write-up every Monday, no spam, unsubscribe anytime.
Subscribe to the newsletter